-
[엘라스틱서치] ELK (Elasticsearch + Logstash + Kibana) 테스트 설정BackEnd/Elasticsearch 2024. 2. 26. 15:00
엘라스틱 서치를 공부하기위해서 기본 설정을 진행
0. ELK 역할
분산 검색엔진으로 역할 : Elasticsearch
Mysql의 정보를 Elasticsearch로 옮기는 역할 : Logstash
데이터의 시각화와 console창을 제공하는 역할 : Kibana
WAS 역할 : Springboot
이번에 사용할 주요역할은 위와 같고 그외에 역할은 좀 더 공부하면서 찾아보아야 한다.
https://github.com/JEONSEUNGREE/ELKStack.git
GitHub - JEONSEUNGREE/ELKStack: ELKStack
ELKStack. Contribute to JEONSEUNGREE/ELKStack development by creating an account on GitHub.
github.com
1. 실행방법
이미 도커컴포즈환경으로 구성
1. 도커,도커컴포즈 설치
2. git clone https://github.com/JEONSEUNGREE/ELKStack.git
3. 도커 네트워크 구성 명령어 실행 docker network create --driver bridge --subnet 172.25.0.0/16 es-stack
4. docker-compose.yml이 있는 디렉토리 위치에서 명령어 실행 docker compose up
(단 OS가 Window, 맥인 경우 도커가 VM으로 동작해서 도커 네트워크 사용이 로컬에서 불가함 포트포워딩으로 변경해서 사용해야한다)
램은 16G 이상이 권장된다.
2. 도커 컴포즈 설정
docker-compose.yml
version: '3.8' services: elasticsearch1: image: elasticsearch:8.12.1 container_name: elasticsearch1 volumes: # 모든 노드 공통 변수용 설정 파일 - ./elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml environment: - ES_JAVA_OPTS=-Xms1024m -Xmx1024m # JVM 시작 최소,최대 메모리 제한 1GB - xpack.security.enabled=false # 엘라스틱 8이상부터의 보안 기능 (테스트용으로 꺼둔다) - cluster.name=elk-cluster # 클러스터명 - bootstrap.memory_lock=true # 메모리 스왑방지한다. (사용되지 않는 메모리를 디스크로 스왑하는 경우 방지) - node.name=elasticsearch1 # 현재 엘라스틱 서치 노드 명 - discovery.seed_hosts=elasticsearch2,elasticsearch3 # 클러스터 형성시 노드 목록 - cluster.initial_master_nodes=elasticsearch1,elasticsearch2,elasticsearch3 # 초기에 마스터 노드로 선출될 수 있는 노드의 목록 mem_limit: 2g # 컨테이너가 사용할 수 있는 최대 메모리를 제한 ulimits: # 컨테이너 프로세스의 리소스 제한 memlock: # 메모리 잠금 soft: -1 hard: -1 ports: - "9200:9200" networks: - es-stack elasticsearch2: image: elasticsearch:8.12.1 container_name: elasticsearch2 volumes: - ./elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml environment: - ES_JAVA_OPTS=-Xms1024m -Xmx1024m - xpack.security.enabled=false - cluster.name=elk-cluster - bootstrap.memory_lock=true - node.name=elasticsearch2 - discovery.seed_hosts=elasticsearch1,elasticsearch3 - cluster.initial_master_nodes=elasticsearch1,elasticsearch2,elasticsearch3 mem_limit: 2g ulimits: memlock: soft: -1 hard: -1 ports: - "9201:9200" networks: - es-stack elasticsearch3: image: elasticsearch:8.12.1 container_name: elasticsearch3 volumes: - ./elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml environment: - ES_JAVA_OPTS=-Xms1024m -Xmx1024m - xpack.security.enabled=false - cluster.name=elk-cluster - bootstrap.memory_lock=true - node.name=elasticsearch3 - discovery.seed_hosts=elasticsearch1,elasticsearch2 - cluster.initial_master_nodes=elasticsearch1,elasticsearch2,elasticsearch3 mem_limit: 2g ulimits: memlock: soft: -1 hard: -1 ports: - "9202:9200" networks: - es-stack logstash: image: logstash:8.12.1 container_name: logstash volumes: - ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml # 모니터링할 엘라스틱 서치 노드 목록 - ./logstash/mysql-connector-j-8.3.0.jar:/usr/share/logstash/mysql-connector-j-8.3.0.jar # java기반인 lostash에서 mysql정보를 가져오기 위한 드라이버 - ./logstash/last_run_metadata:/usr/share/logstash/last_run_metadata # 증분을 위한 메타 정보로 마지막으로 엘라스틱 서치에 넣은 mysql row 순번을 기록한다. - ./logstash/pipeline:/usr/share/logstash/pipeline # mysql -> logstash -> 엘라스틱 서치가 연결될 주요 설정 파일들 - ./logstash/config/pipelines.yml:/usr/share/logstash/config/pipelines.yml # 설정한 pipeline의 정보를 맵핑 - ./logstash/template:/usr/share/logstash/template # 엘라스틱 서치에 생성할 인덱스 구조 depends_on: - elasticsearch1 - elasticsearch2 - elasticsearch3 - elk-mysql networks: - es-stack elk-mysql: image: mysql:8.3.0 restart: always container_name: elk-db environment: MYSQL_ROOT_PASSWORD: root MYSQL_DATABASE: esstack ports: - "4556:3306" volumes: - ./mysql/init.sql:/docker-entrypoint-initdb.d/init.sql # 초기에 설정할 디비 스키마 networks: - es-stack kibana: image: kibana:8.12.1 container_name: kibana environment: - ELASTICSEARCH_HOSTS=http://elasticsearch1:9200 ports: - "5601:5601" networks: - es-stack depends_on: - elasticsearch1 networks: # 도커 브릿지 네트워크로 구성 es-stack: external: true3. losgstash + mysql + elasticsearch 구성
logstash/pipeline/product.conf
logstash 실행시 등록할 수 있는 설정파일
단 logstash/config/pipelines.yml 설정 파일에서 이 product.conf를 맵핑하거나 새로운 설정 파일을 만들어서 적용할 수 있다.
실제 logstash에서 사용할지 여부는 logstash/config/pipelines.yml로 결정
input { jdbc { jdbc_connection_string => "jdbc:mysql://elk-mysql:3306/search" # elk-mysql은 도커 컴포즈에서 설정한 서비스 이름으로 도커 네트워크에서 자동으로 dns로 잡아준다. jdbc_user => "root" # mysql 아이디 jdbc_password => "root" # mysql 패스워드 jdbc_driver_library => "/usr/share/logstash/mysql-connector-j-8.3.0.jar" # mysql 드라이버 경로 (도커 컴포즈 볼륨마운트로 이미 맵핑) jdbc_driver_class => "com.mysql.cj.jdbc.Driver" # 사용할 JDBC 클래스 schedule => "* * * * *" # msyql 조회할 시간 스케줄링 (cronjob 검색해보면 알 수 있다) statement => "SELECT * FROM product WHERE product_id > :sql_last_value" # 마지막 아이디를 통해 조회하여 데이터 추가시 확인 use_column_value => true # sql_last_value을 사용하여 쿼리의 WHERE 조건을 동적으로 생성. tracking_column => "product_id" # 추적할 컬럼 이름 sql_last_value tracking_column_type => "numeric" # 추적할 컬럼의 타입 숫자형 지정 last_run_metadata_path => "/usr/share/logstash/last_run_metadata/.logstash_product_dummy" # 마지막 실행 정보를 저장할 파일 경로이며 logstash_product_dummy로 저장됨 } } filter { date { match => ["date", "yyyy-MM-dd HH"] # 입력 데이터의 date 필드 형식을 지정 timezone => "Asia/Seoul" # 시간대를 'Asia/Seoul'로 설정 } } output { elasticsearch { hosts => ["http://elasticsearch1:9200", "http://elasticsearch2:9200", "http://elasticsearch3:9200"] # 데이터를 전송할 Elasticsearch 호스트의 주소 목록 index => "product-%{+YYYY.MM.dd}" # 데이터를 저장할 Elasticsearch 인덱스의 이름 패턴 날짜 형식을 사용해 동적으로 인덱스 이름 생성 template => "/usr/share/logstash/template/product.json" # Elasticsearch에 사용할 인덱스 템플릿 파일의 경로 template_name => "product" # Elasticsearch 인덱스 템플릿의 이름 template_overwrite => true # 기존의 동일한 이름을 가진 인덱스 템플릿이 존재할 경우 덮어쓰기 설정 true이면 덮어쓰기를 허용함 } }4. 상품 정보 설정
logstash/config/pipelines.yml
- pipeline.id: product path.config: "/usr/share/logstash/pipeline/product.conf" - pipeline.id: category path.config: "/usr/share/logstash/pipeline/category.conf" - pipeline.id: product_category path.config: "/usr/share/logstash/pipeline/product_category.conf"각 설정 파일을 참고하여 logstash 실행시 데이터스트림 정보 구성
5. 엘라스틱 서치 인덱스 템플릿
logstash/template/product.json
{ "index_patterns": ["product-*"], "template": { "settings": { "number_of_shards": 1, "number_of_replicas": 1 }, "mappings": { "properties": { "product_id": { "type": "long" }, "description": { "type": "text" }, "image_url": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "price": { "type": "integer" }, "product_name": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } }, "priority": 1, "version": 1 }6. Mysql 실행시 초기화할 스키마, 테이블 정보
mysql/init.sql
-- utf8mb4_unicode_ci로 한글 설정 CREATE DATABASE IF NOT EXISTS search CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci; USE search; create table category ( category_id bigint auto_increment primary key, category_name varchar(255) not null, parent_id bigint null, foreign key (parent_id) references category (category_id) ); create table product ( product_id bigint auto_increment primary key, description varchar(2000) null, image_url varchar(255) not null, price int not null, product_name varchar(255) not null ); create table product_category ( product_category_id bigint auto_increment primary key, category_id bigint null, product_id bigint null, foreign key (product_id) references product (product_id), foreign key (category_id) references category (category_id) );7. 증분 메타 데이터
ogstash/last_run_metadata/.logstash_product_dummy 마지막 인덱스 정보
cat .logstash_product_dummy 명령어 실행시 다음과같이 마지막 인덱스 정보를 갖고있을을 알 수 있다.
예시 값 ) --- 50000
이를 통해서 엘라스틱서치에 Mysql 정보를 넣을때 데이터를 Full로 다시 넣지 않고 증분하여 넣을 수 있다.
만약에 도커 컴포즈를 재 실행하면 ./logstash_product_dummy가 남은 경우 그 정보를 바탕으로 인덱스를 조회한다.
8. 스프링 부트
테스트용 임시 데이터 상품, 카테고리 설정하고 CommandLineRunner를 통해서 스프링 부트 시작시 자동으로 mysql에 데이터를 넣도록 설정했다.
9. Kibana 조회

터미널에서 docker compose up 실행 http://localhost:5601/app/dev_tools#/console kibana의 콘솔창으로 이동
GET / # 클러스터 정보, 상태 확인 GET /_cat/indices # 인덱스 목록, 정보 확인 GET /[인덱스명]/_mapping # 인덱스 필드 타입및 정보 확인 POST /[인덱스명]/_search # 인덱스 정보 확인 조회 (한글은 노리분석기 플러그인을 설치해야 한다.) { "query": { "match": { "product_name": "Concrete" } } }
kibana에서 확인한 인덱스 목록 정보 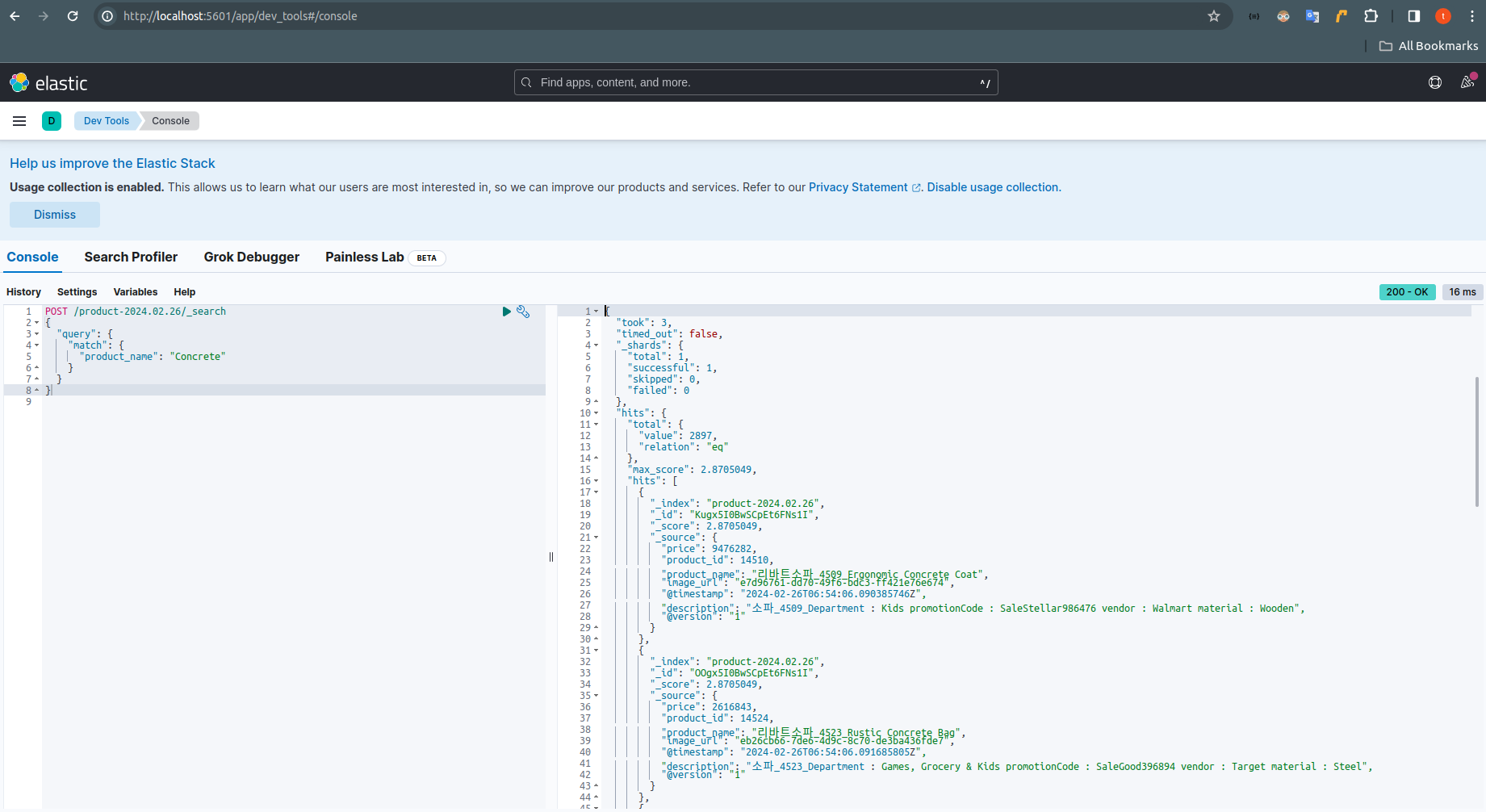
kibana에서 인덱스 검색 더미데이터는 ELK 연동을 위한 임시 정보이다.
10. 앞으로 테스트할 정보
1. 노드가 3개로 구성되었기때문에 logstash/template/product.json에서 샤드와 레플리카를 수정하여 인덱스를 분산 저장한다.
2. 분산 저장 도중 elasticsearch 노드 삭제해보기
3. 분산 저장 후 elasticserach 노드 삭제해보기
4. 노드 추가 후 풀인덱싱 해보기
5. 복잡한 이커머스 더미테이터 만들어서 msyql과 속도 비교해보기
(컴퓨터 한대에서 클러스터에서 다중 노드는 컴퓨팅 파워가 느껴지지 않을 것같다고 생각하는데 제한된 환경이기 때문에 그래도 테스트는 해볼 예정이다 꼭 클러스터에 노드가 여러대고 개별 물리 컴퓨터로 구성된다면 컴퓨팅 파워는 좋겠지만 네트워크 비용도 있고 여러가지 고려사항이 존재한다)
6. 집계 데이터 처리 속도 비교해보기
'BackEnd > Elasticsearch' 카테고리의 다른 글
[엘라스틱서치] 엘라스틱 서치 실무 가이드 (0) 2024.02.05