-
[DB] 인덱스를 걸었는데 느린 이유BackEnd/DB 2024. 6. 13. 16:25
0. 인덱스가 느리다는 커뮤니티 글
1. 문제상황
최근에 커뮤니티를 보다가 DB관련 질문을 확인했다.

부하가 걸리는 데이터 특정 날짜 기준 이상을 넘어가면 인덱스를 사용해도 느리다는 것이다.
근데 7일단위에서 걸면 빠르고 8일 이상인경우는 느리다는 것이다.
보고 아래와 같이 답글을 달았다.
2. 추정

책에서 경험했던 그대로 인덱스에 대한 기초에 대해서 설명해 주었다. 정확하게는 실행계획보다는 트레이스를 보고싶었는데 작성자가 올리지않았다.
3. 해결방안
작성자가 맞는것 같다는데 그럼 해결방안이 궁금하다고 질문을 남겼다.

1. 인덱스
1. 정의
우선 인덱스에 대해서 다시한번 짚고 넘어간다.
인덱스는 사전에 앞에 목차 처럼 찾기위한 단어를 쭉 나열해둔 것일뿐이고 실제 데이터는 목차에서본 단어의 페이지 번호로 찾아가야 알 수 있다. 그렇기 때문에 찾아가는 비용이 발생한다.
만약에 찾는 사전에서 목차에 따라서 단어를 찾는데 전세계의 언어가 다 들어있는 단어라면 우리는 목차를 찾아서 페이지를 찾았어도 바로 데이터를 찾지 못하고 해당 페이지에서 다시한번 우리가 원하는 언어를 찾아야 할 것이다.
목차를 썼지만 쓰지 않은 느낌을 주는게 잘못 설계된 인덱스다.
만약에 인덱스 컬럼에서 between과 같은 범위 조건이 들어있다면 해당 컬럼은 필터로 동작해서 access접근 방식보다 느릴수밖에없다.
filter를 최대한 줄이는게 좋다.
아래의 실행계획을 보면 인덱스가 찾아가는 방식에 대해 알 수 있다.
2. 예시
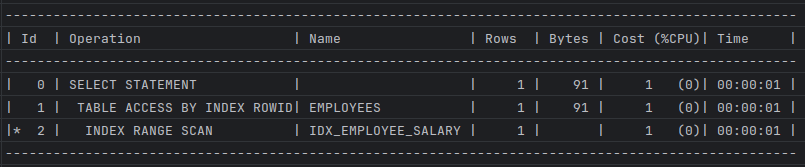
// 인덱스 생성 CREATE INDEX idx_employee_salary ON employees(salary); // 실행 계획 EXPLAIN PLAN FOR select /*+ idx_employee_salary(e) */ * from employees e where salary = 3000; // 결과 확인 SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);3. 실행 계획
아래의 실행결과 확인 시 INDEX ROWID를 확인 할 수 있다.
인덱스를 확인하는 이유는 소량의 데이터를 빨리 찾기위해서 인덱스에서 테이블레코드를 찾아가기위한 주소값인 ROWID를 얻으려는 목적에 있다.
이 ID는 물리적인 요소인 데이터 파일 번호, 오브젝트 번호, 블록 번호 같은 요소로 구성되어있는데 물리적으로 직접 연결된것이 아닌 테이블 레코드를 찾아가기 위한 논리적 주소 정보를 담고있다. 따라서 논리적 주소라고 할 수 있다.
2. 해결방안
그럼 데이터가 100만건 이상이고 인덱스를 날짜로 걸때 어떻게 해야 속도를 최적화 할 수있을지 많이 생각해봤다.
작성자분께는 답글로 데이터가 너무 많아서 캐시 적중률로 해결할 문제는 아니고 데이터 구조(클러스터링 구조)를 변경하거나 병렬로 스캔을 걸어보라고 했다. 하지만 실 개발 환경에서 데이터 구조를 바꾸는건 힘들것같고 병렬로 리소스 자원을 사용하는 것도 큰 무리가 있다면 코드로써 어떻게 해결 할 수 있을지 고민을 했다.
결국에 날짜를 인덱스를 걸어도 between이라는 스캔범위는 수직적으로 정확히 데이터를 타고 들어갈 수 없다.
데이터양이 많다면 수평적으로 스캔이 많이 이루어질텐데 심지어 테이블 풀 스캔보다 SingleBlock형태라서 더 불리하다.
친절한 SQL 튜닝 책을 참고해서 여러 방안을 생각해봤다.
0. 데이터 테스트를 위한 예시 코드
// 테이블 생성 create table TestSoldTable as select rownum cusId , '2018' || lpad(ceil(rownum/100000), 2, '0') soldMonth , decode(mod(rownum,12), 1, 'A', 'B') soldType , round(dbms_random.value(1000,100000), -2) soldPrice from dual connect by level <= 400000; // 2번만 반복 INSERT INTO TestSoldTable SELECT rownum + 400000 cusId , '2018' || lpad(ceil((rownum + 400000)/100000), 2, '0') soldMonth , DECODE(MOD(rownum + 400000, 12), 1, 'A', 'B') soldType , ROUND(DBMS_RANDOM.value(1000, 100000), -2) soldPrice FROM dual CONNECT BY level <= 400000; // 성능 테스트에 사용할 쿼리 select count(*) from TestSoldTable where soldType = 'A' and soldMonth between '201801' and '201812'; // 인덱스 생성 선두컬럼 날짜 create index TestSoldTable_IDX2 on TestSoldTable(soldMonth, soldType);튜닝전 인덱스의 트레이스

읽은 블록 I/O 3345개 시간은 위와 같다.
1. 데이터량이 어플리케이션 단에서 페이징을 한다.
단 한번에 가져와야한다면 다른 얘기일 수 있다.
2. 병렬로 데이터를 스캔해본다.
// 트레이스 시작 ALTER SESSION SET SQL_TRACE = TRUE; // 병렬로 걸어 본다. (2번 일부러 인덱스로 설정 -> 날짜 선두컬럼) SELECT /*+ PARALLEL(t 4) INDEX(t TESTSOLDTABLE_IDX2) */ COUNT(*) FROM TestSoldTable t WHERE soldType = 'A' AND soldMonth BETWEEN '201801' AND '201812'; // 트레이스 종료 ALTER SESSION SET SQL_TRACE = FALSE;트레이스 파일에서 읽어본 내용

병렬 처리 병렬로 스캔한경우 읽은 블록 I/O는 튜닝전과 동일하며 속도는 반정도 단축됬다.
3. Between을 IN-List로 전환
범위마다 반복하면서 인덱스를 탄다고 보면된다.
한번에 안하고 계속 조건마다 반복해서 느릴수있다고 생각하지만 수직적 탐색속도 때문에 훨씬 빠르다.
단 날짜를 대신 In에 넣어줘야하고 수직 깊이, 날짜 범위가 지나치게 넓게 설정되지않는다면 좋을 것 같다.

이전 스캔들보다 블록 I/O가 1/10가량 줄었고 속도도 훨씬 빨라졌다.
4. Index Skip Scan
보통 인덱스의 선두컬럼이 있는 여부에 따라서 인덱스가 동작하는데 선두 컬럼없이도 동작하는 방식이며
조건절에서 빠진 인덱스의 선두 컬럼의 유니크한 수가 적고 후행 컬럼의 유니크한 수가 많을때 유용하다.

이전 스캔들보다 제일 블록 I/O가 적다
3. 결론
조건에 따라서 테스트를 해보고 맞는 방법을 사용하는게 중요하다.
'BackEnd > DB' 카테고리의 다른 글
[DB] 친절한 SQL 튜닝 - 인덱스 (0) 2024.06.12 [DB] 친절한 SQL 튜닝 - 속도, 저장 구조 (0) 2024.06.10 [DB] 친절한 SQL 튜닝 - SQL 처리 과정, 실행 계획 (0) 2024.05.28